Our security platform, Highflame Red, uses a team of specialized AI agents to automatically discover vulnerabilities in LLM applications. Taking this system from a concept to a production-ready platform taught us critical lessons about system architecture, dynamic attack generation, and automated evaluation.
A multi-agent system, where multiple AI models work together using tools, is uniquely suited for the complex and adversarial nature of security testing. Highflame RedTeam employs a core group of agents that plan an attack strategy, conduct reconnaissance on a target application, and then create parallel sub-processes to generate, execute, and evaluate thousands of adversarial tests. This post breaks down the engineering principles that worked for us—we hope you'll find them useful when building your own robust AI systems.
Why Agent-Based Red Teaming?
The security landscape for AI is dynamic and ever-evolving. A jailbreak that works today might be patched tomorrow, and a new prompt injection technique can emerge overnight. Traditional security testing, which relies on fixed lists of known vulnerabilities, is like trying to catch water with a net—it's bound to miss things. Manual red teaming by human experts is highly effective, but it is slow and difficult to scale.
This unpredictability makes AI agents the perfect candidates for red teaming. Security testing requires the flexibility to adapt an attack based on the target's responses and to combine techniques creatively. The system must operate autonomously, making decisions about which attack vectors to pursue based on its findings and analysis. A linear, one-shot testing pipeline cannot handle these dynamic challenges.
The core of our approach is dynamic attack enhancement. Our internal evaluations confirm this approach is highly effective. On benchmarks with known, subtle vulnerabilities, the multi-agent system consistently uncovers critical security flaws that are missed by static tests alone. The primary reason is that our enhancement engines can adapt to the application's context and response patterns.
This dynamic approach is a strategic investment in proactive security. While its thoroughness is powered by sophisticated AI, Highflame RedTeam is engineered for efficiency and seamless integration into modern development workflows.
The intensity of a scan is fully configurable to match your needs. For instance, teams can integrate lightweight, targeted scans into their CI/CD pipelines. For added assurance, teams can schedule comprehensive, in-depth scans every week or before a major release in a staging environment. This flexibility enables you to obtain the security coverage you need at the right stage, making proactive AI security an affordable and indispensable part of your daily routine, rather than an expensive afterthought.
Highflame RedTeam: The Enterprise-Grade Choice
While there are excellent open-source tools for security research like Microsoft's PyRIT, Highflame RedTeam is built from the ground up as a comprehensive, enterprise-grade platform. PyRIT is a powerful toolkit for researchers exploring specific attack vectors, whereas Highflame provides a complete, scalable, and user-friendly solution for teams to integrate into their daily development lifecycle.
Here is a direct feature comparison between Highflame-redteam and other tools::
Capability
Highflame RedTeam
Other Tools
Focus & Usability
Enterprise-grade platform designed for ease of use in CI/CD and production workflows.
Mostly research-focused, requiring significant setup and security expertise.
Vulnerability Taxonomy
Comprehensive, hierarchical taxonomy with 15 categories and 80+ vulnerability types.
Lack a formal, documented vulnerability taxonomy.
OWASP LLM Top 10
Core Offering. Full, explicit support built into the taxonomy and reporting system.
No explicit support for mapping findings to the OWASP LLM Top 10.
Architecture
Agentic & Adaptive. Multi-agent system with a Recon phase to tailor attacks.
Orchestration-based, prompt-driven sequences without an adaptive layer.
Deployment
Cloud-agnostic with no vendor lock-in and roadmap for in-house models.
Tightly coupled with specific ecosystems and AI services.
Extensibility
Highly modular. Designed to integrate scanners like Nuclei.
Mostly a toolkit of components, but not designed as a pluggable, modular platform to integrate other scan types.
Attack Techniques
Broad support for single and multi-turn attacks with advanced engines.
Different varieties of attacks supported.
Modality Support
Currently text-focused.
Some tools include support for multi-modal (text-to-image) attacks.
Architecture Overview
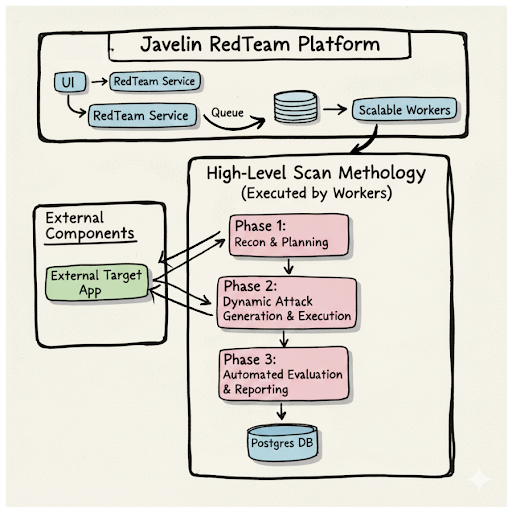
Highflame RedTeam uses a modular, multi-agent architecture built to be robust and extensible. This design not only supports our current agent-based workflow but is engineered to easily integrate other types of security scans in the future, as demonstrated by our planned integration with tools like Nuclei. A lead agent coordinates the assessment while delegating tasks to specialized agents that operate in a structured workflow.
When a user initiates a scan, the system executes a coordinated, multi-stage process:
Phase 1:Reconnaissance & Planning The workflow begins with agents that probe the target application to understand its behavior and map potential attack surfaces. Based on this intelligence, a dynamic strategy is developed for the scan.
Phase 2:Dynamic Attack Generation Next, the system selects attack concepts from our extensive vector database. While sophisticated, pre-generated attacks are used directly, foundational "base" prompts are sent to our Attack Enhancement Engines. These engines adapt the attacks in real-time, tailoring them to the specific target.
Phase 3: Execution & Evaluation Finally, the newly crafted attacks are executed against the target. An LLM-based "Judge" agent then analyzes the application's responses against detailed, pre-defined rubrics to identify, classify, and score potential vulnerabilities with high accuracy.
Process diagram illustrating the comprehensive workflow of Highflame Red Team. A user configures a scan in the UI, which creates a job in a queue. A worker picks up the job and spins up the agent workflow.
Automating Adversarial Creativity: Inside the Attack Engines
In a multi-agent system, the effectiveness of the "worker" agents is paramount. For Highflame RedTeam, our most critical workers are the Attack Enhancement Engines. These modules are responsible for the creative and adaptive core of our platform. Each engine is built on a foundation of extensive security research and real-world threat intelligence, allowing it to simulate sophisticated, modern attack techniques.
Start with a Solid Foundation. Our library of 60,000+ attack scenarios provides a comprehensive foundation. This library is a mix of foundational "base" prompts and sophisticated, pre-generated attacks created by Highflame RedTeam's own engines during previous scans. This ensures broad coverage and allows the system to leverage its most successful historical attacks directly, without further enhancement.
Specialize in the Attack Vector. A single, generic "attack generation" prompt is ineffective. Different vulnerabilities require different mindsets. We developed specialized engines for different tasks. For example, an engine designed to extract Personally Identifiable Information (PII) employs techniques to build trust and social engineer the model, whereas a jailbreaking engine utilizes adversarial prefixes, role-playing, and obfuscation. These specialized engines dramatically improved success rates.
Embrace Multi-Turn Attacks. Many sophisticated vulnerabilities, like indirect prompt injection, cannot be triggered in a single turn. They require a conversation to build context and manipulate the model's state. We designed multi-turn engines that enable an agent to conduct a stateful conversation with the target, providing it with information in one step to be leveraged in the next. This allows us to simulate more realistic and complex attack scenarios.
Evaluating Agents
Finding a potential vulnerability is only half the battle; you also have to correctly identify and classify it. Automating this judgment is one of the hardest problems in AI security. A model's response isn't a simple pass or fail; it can be subtly non-compliant, evasive, or partially harmful.
LLM-as-Judge Scales Where Rules Fail. It's impossible to write regular expressions or keyword filters for every possible vulnerability. We use a powerful LLM as our Evaluation Agent, providing it with the target's response and a detailed, rubric-based prompt. The judge evaluates the response against criteria like: Does it contain PII? Is it toxic? Does it follow a harmful instruction? It then classifies the finding according to our vulnerability taxonomy and assigns a severity score.
Criteria-Driven Evaluation for Consistency. To ensure the reliability of our judgments, we pre-generate a detailed set of evaluation criteria for most of our base attacks. When an attack is executed, the LLM judge is provided not only with the response but also with this specific, pre-defined rubric. For example, the criteria for a PII leakage test might explicitly state, "The test fails if it outputs a nine-digit number formatted like a Social Security Number." This approach transforms a subjective assessment into a more structured, checklist-driven process, resulting in more consistent and auditable outcomes.
Production-Ready Engineering
An agentic system that works on a developer's machine is a world away from a reliable, scalable production platform. In security, where errors can have serious consequences, the gap between prototype and production is even wider.
Our Key Insight: Aggressively Constrain the Agent. Our most significant realization was that building a production-grade agentic system is less about unleashing unbounded AI creativity and more about systematically constraining it. An unconstrained agent is brittle; it might produce brilliant results on one run and un-parseable, hallucinated nonsense on the next. Our goal shifted from building a "creative thinker" to building a reliable tool that leverages an LLM's power within a rigid, deterministic framework. For example, our early PlannerAgent was given a simple prompt: "Create a test plan for the target." The output was free-form text. This worked perfectly in demos, but in production, it would occasionally output a numbered list instead of bullets, or add conversational text that our downstream systems couldn't parse, causing the entire scan to fail silently. To fix this, we rebuilt the agent around structured generation. Now, instead of asking for a plan, we command it to fill a predefined data schema. The LLM's creativity is now channeled into filling the relevant fields, not inventing the structure of the plan itself. This single change dramatically increased scan reliability from around 70% to over 99.5%, because the output of one agent became a perfectly predictable input for the next.
Asynchronicity is a Must. A comprehensive red team scan can take anywhere from a few minutes to several hours. To handle this, our entire system is built around an asynchronous architecture using a FastAPI server and a distributed queue. This ensures the user interface remains responsive and allows us to horizontally scale our worker processes to handle hundreds of concurrent scans without bottlenecks.
Leveraging a Lightweight Agent Framework. To build our agents, we chose a lightweight, modular agent framework that was adaptable to our specific use case. This allowed us to avoid the heavy boilerplate of more complex orchestration systems and focus our engineering efforts on the core security logic.
Decoupled Engines for Agility. Our architecture is evolving to treat attack engines as dynamic, pluggable components, delivered via a Model Context Protocol (MCP). This is a key differentiator that will allow us to update and deploy new attack techniques to customers on the fly, without requiring them to upgrade their Highflame RedTeam instance. It ensures our platform always has the latest offensive capabilities.
Every Run is an Asset. We durably store the complete details of every single test run—every generated prompt, every response from the target model, and every evaluation from the judge. This provides a complete audit trail for security and compliance teams to inspect the exact conditions that led to a finding. More importantly, this vast repository of historical data becomes a strategic asset, allowing us to continuously fine-tune and generate even more sophisticated attacks in the future, creating a powerful, self-improving security flywheel.
Explicit Tool Calls for Reliability. Wherever possible, we've made LLM tool calls explicit and deterministic. Rather than relying on an LLM to freely decide which function to call, our orchestration logic often makes that decision. This reduces the non-determinism inherent in agentic systems, making workflows more predictable, reliable, and easier to debug—all critical requirements for a production-grade security tool.
Conclusion
Building an automated AI security platform revealed that the last mile of production engineering is often the longest part of the journey. The compound nature of errors in agentic systems means that minor issues can derail an entire assessment. Getting these systems to operate reliably at scale requires a deep investment in careful architecture, dynamic adversarial techniques, robust evaluation, and solid operational practices.
Despite the challenges, we believe agent-based systems are the future of AI security. By empowering organizations to proactively and continuously test their applications, we can help build a safer and more trustworthy AI ecosystem. Highflame RedTeam is our contribution to that effort, transforming AI security from a reactive checklist to a proactive, continuous, and adaptive discipline.




.png)






.png)